Neural Volumetric Object Selection
Zhongzheng Ren1
Aseem Agarwala2†
Bryan Russell2†
Alexander G. Schwing1†
Oliver Wang2†
(† indicates alphabetic order)
1UIUC 2Adobe Research
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Paper | Data | Bibtex | Slides | Poster
Video (CVPR talk)
Abstract
We introduce an approach for selecting objects in neural volumetric 3D representations, such as multi-plane images (MPI) and neural radiance fields (NeRF). Our approach takes a set of foreground and background user scribbles in one or more views and automatically estimates a 3D segmentation of the desired object, which can be rendered into novel views. To achieve this result, we propose a novel voxel feature embedding that incorporates multi-view features from the neural volumetric 3D representation and image features from all input views. To evaluate our approach, we introduce a new dataset of human-provided segmentation masks for depicted objects in real-world multi-view scene captures. We show that our approach out-performs strong baselines, including 2D segmentation and 3D segmentation approaches adapted to our task.
Method
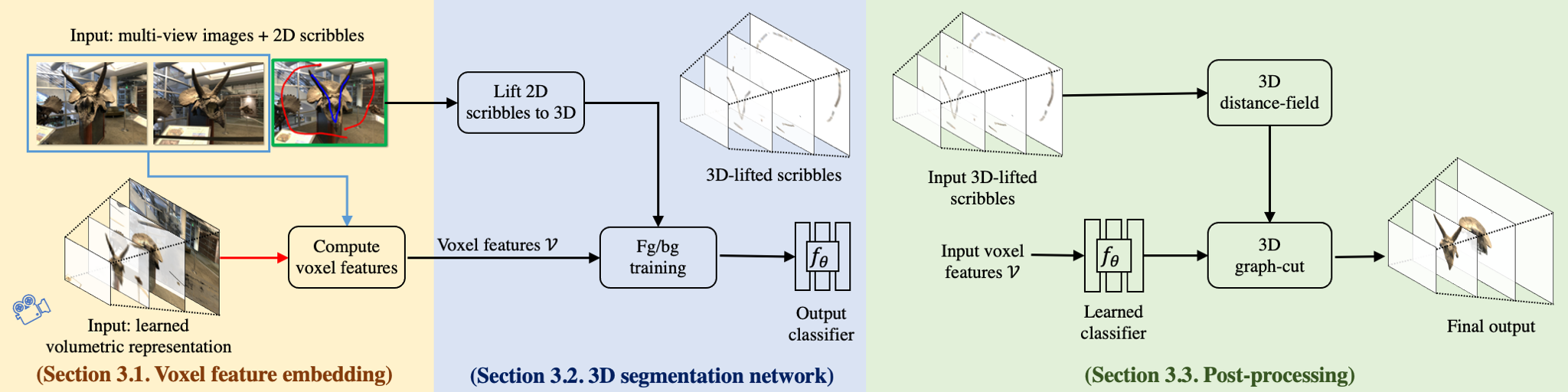
Approach Overview. For each voxel in the 3D volume, we first compute a voxel feature embedding (left). We then train a 3D segmentation network to classify each voxel into foreground or background using as supervision the partial user scribbles (center). We apply the learned classifier and further refine the result using a 3D graph-cut which uses the 3D distance field of the scribbles (right).
Results

For each scene, we show the reference view image and the input scribbles on the left. We then show the 2D mask and corresponding foreground image computed by different methods. On the right-most column, we show the ground-truth. Note that the foreground segmentation of the 2D baselines are not rendered; we apply the inferred mask to the ground truth test image.
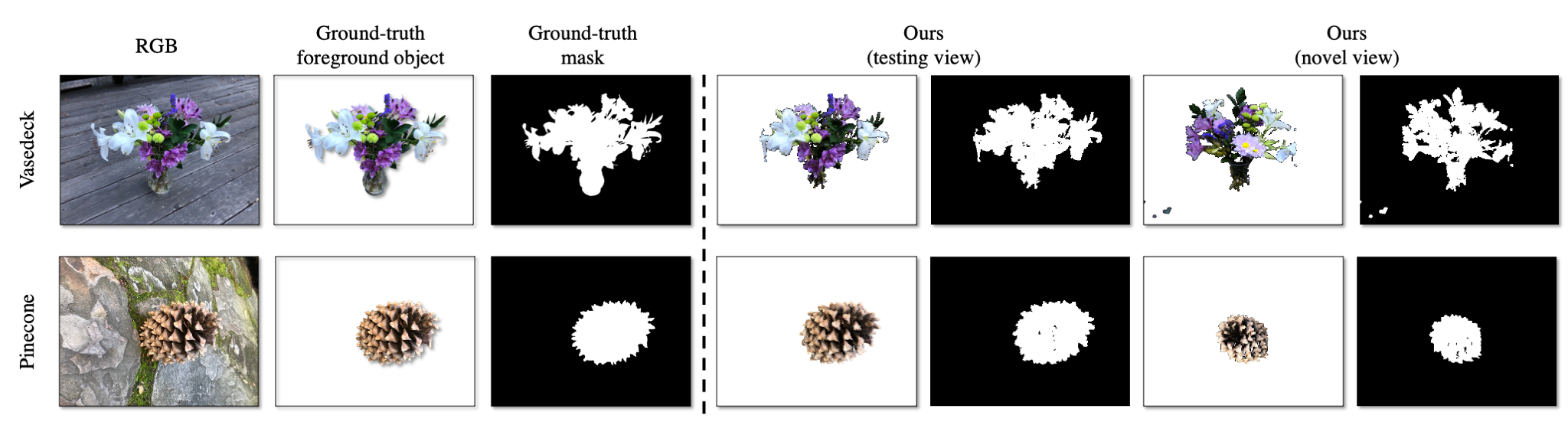
Results on the NeRF-real360 using PlenOctrees as neural volumetric representation.
Dataset (mask & scribbles)

Scribbles: we annotate a fixed set of foreground-background scribbles per image. For each scene, we have one pair of foreground and background scribbles for the reference view. Note that a scribble may contain several strokes. Mask: we obtain the high-quality ground-truth annotations using a professional service.
Related Work
B. Mildenhall, et al., NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV 2020.
T. Zhou, et al., Stereo Magnification: Learning View Synthesis using Multiplane Images. SIGGRAPH 2018.
S. Wizadwongsa, et al., NeX: Real-time View Synthesis with Neural Basis Expansion. CVPR 2021.
A. Yu, et al., PlenOctrees for Real-time Rendering of Neural Radiance Fields. ICCV 2021.
A. Yu, et al., Plenoxels: Radiance Fields without Neural Networks. CVPR 2022.
Acknowledgement
This work is supported in part by NSF #1718221, 2008387, 2045586, 2106825, MRI #1725729, NIFA 2020-67021-32799 and Cisco Systems Inc. (CG 1377144 - thanks for access to Arcetri). ZR is supported by a Yee Memorial Fund Fellowship. We also thank the SPADE folks for the webpage template.