Not All Unlabeled Data are Equal:
Learning to Weight Data in Semi-supervised Learning
Zhongzheng Ren* Raymond A. Yeh* Alexander G. Schwing
(*equal contribution)
University of Illinois at Urbana-Champaign (UIUC)
Neural Information Processing Systems (NeurIPS), 2020
Paper | Code | Slides | Bibtex
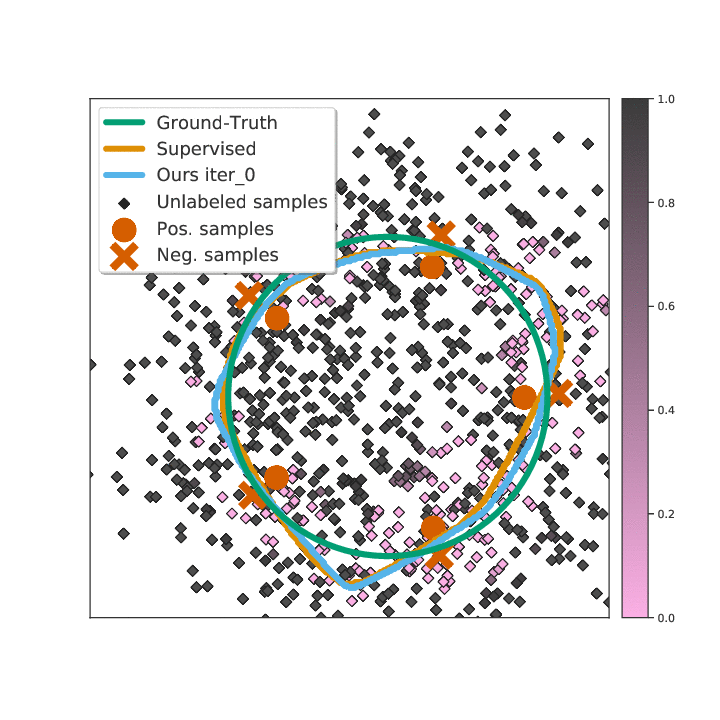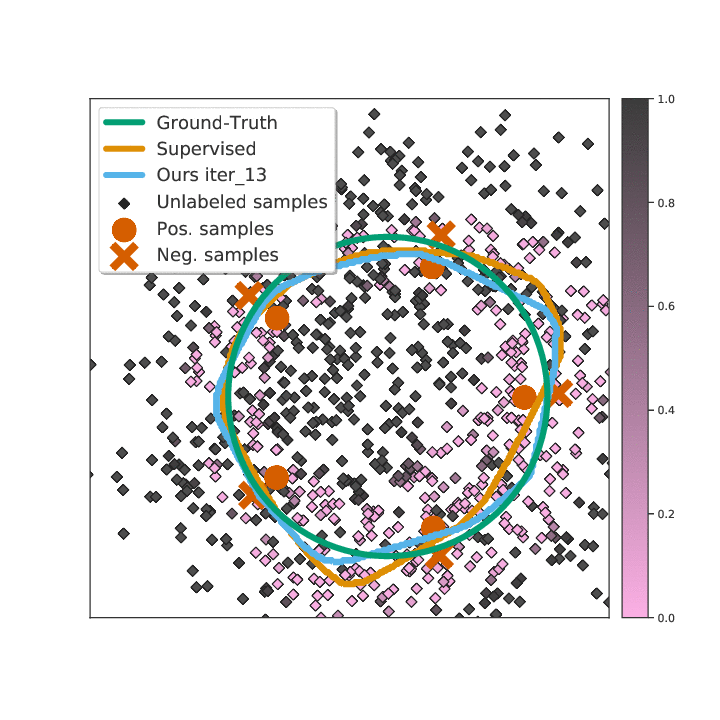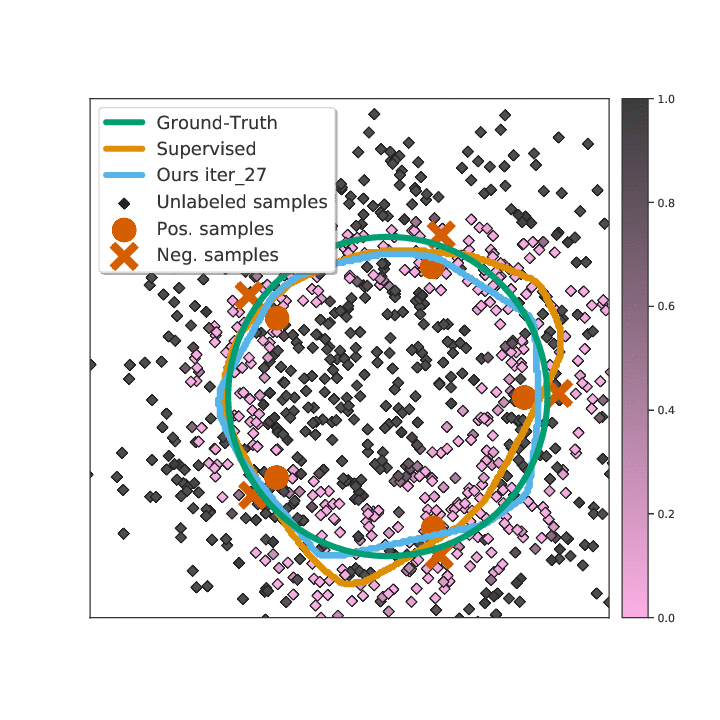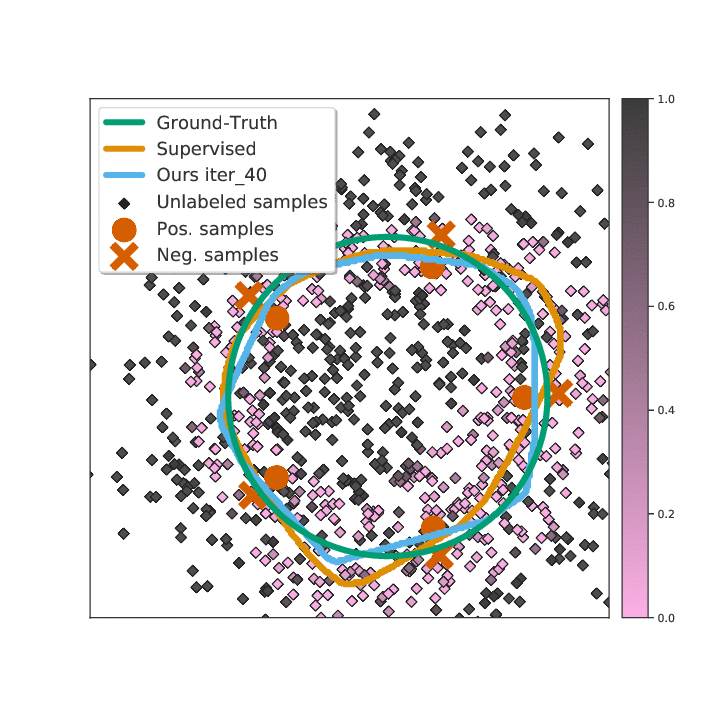
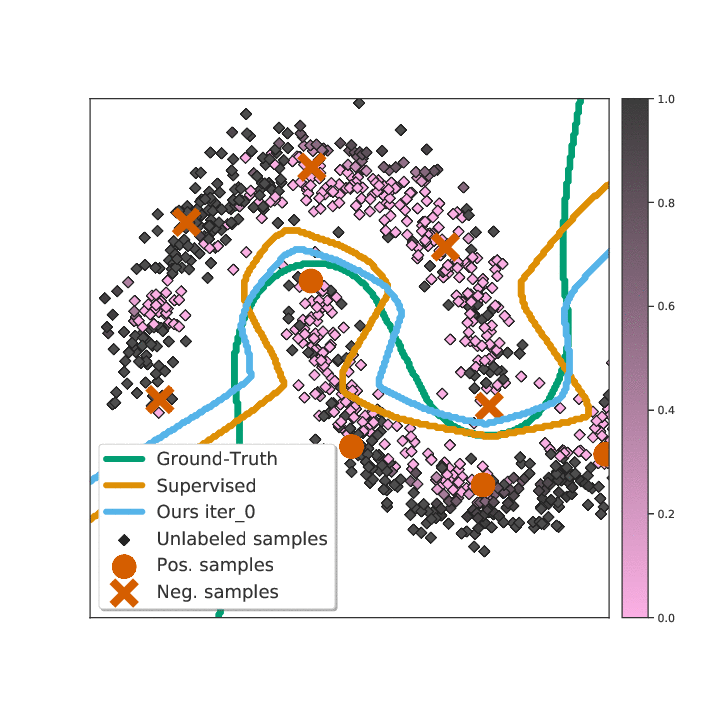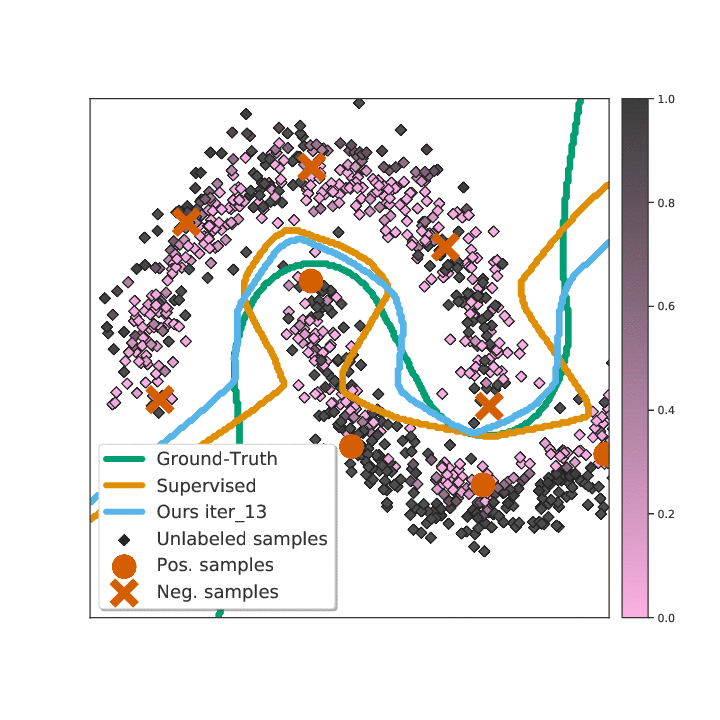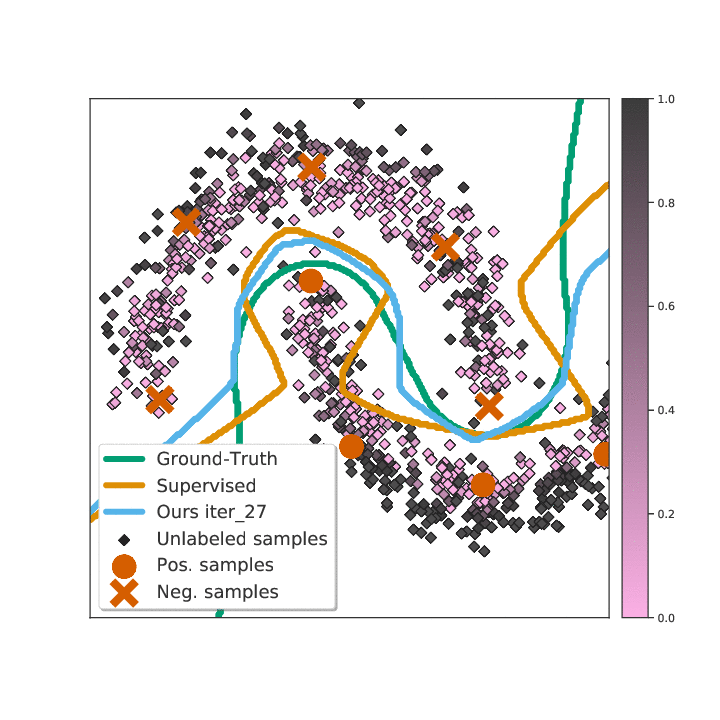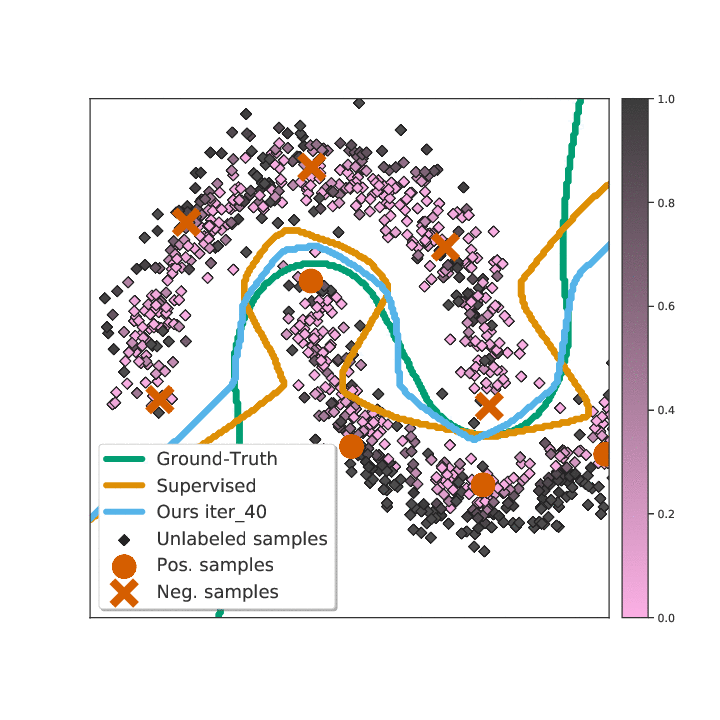
Abstract
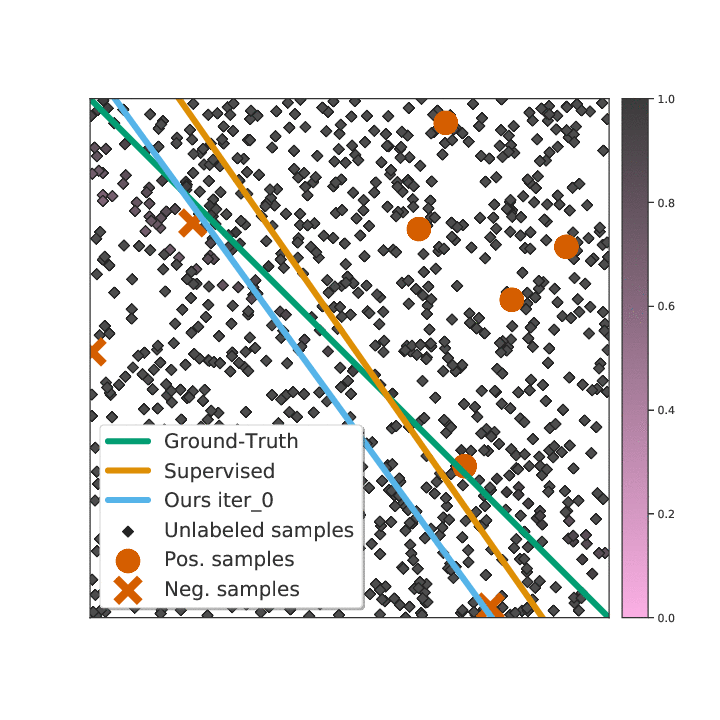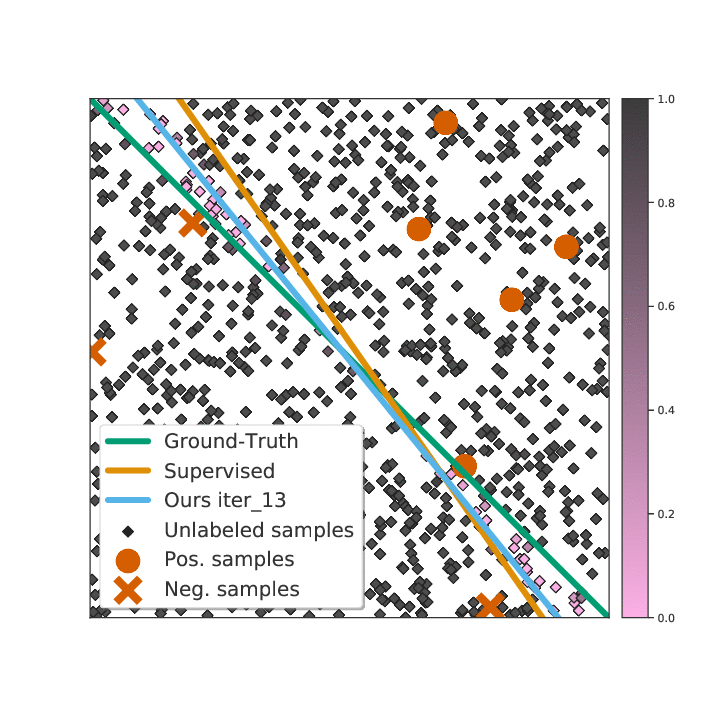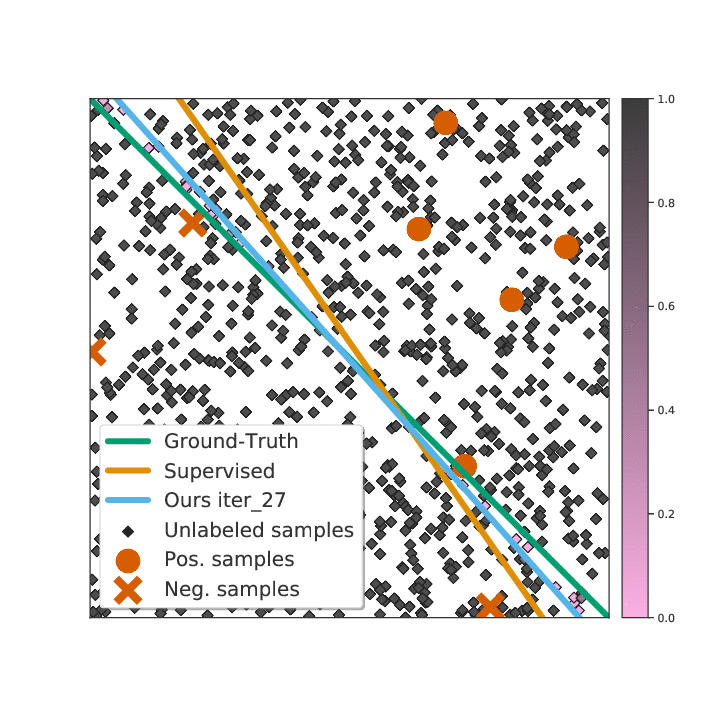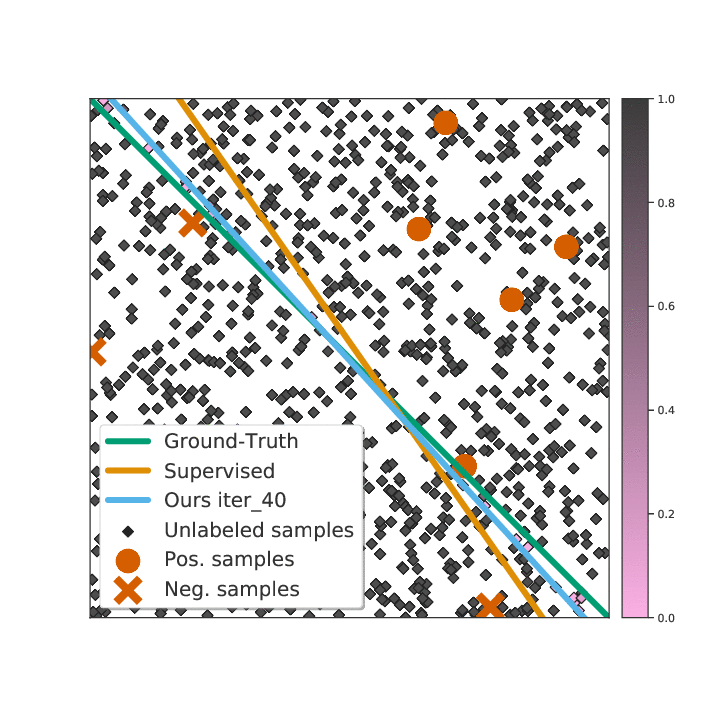
Existing semi-supervised learning (SSL) algorithms use a single weight to balance the loss of labeled and unlabeled examples, i.e., all unlabeled examples are equally weighted. But not all unlabeled data are equal. In this paper we study how to use a different weight for every unlabeled example. Manual tuning of all those weights -- as done in prior work -- is no longer possible. Instead, we adjust those weights via an algorithm based on the influence function, a measure of a model's dependency on one training example. To make the approach efficient, we propose a fast and effective approximation of the influence function. We demonstrate that this technique outperforms state-of-the-art methods on semi-supervised image and language classification tasks.
NeurIPS materials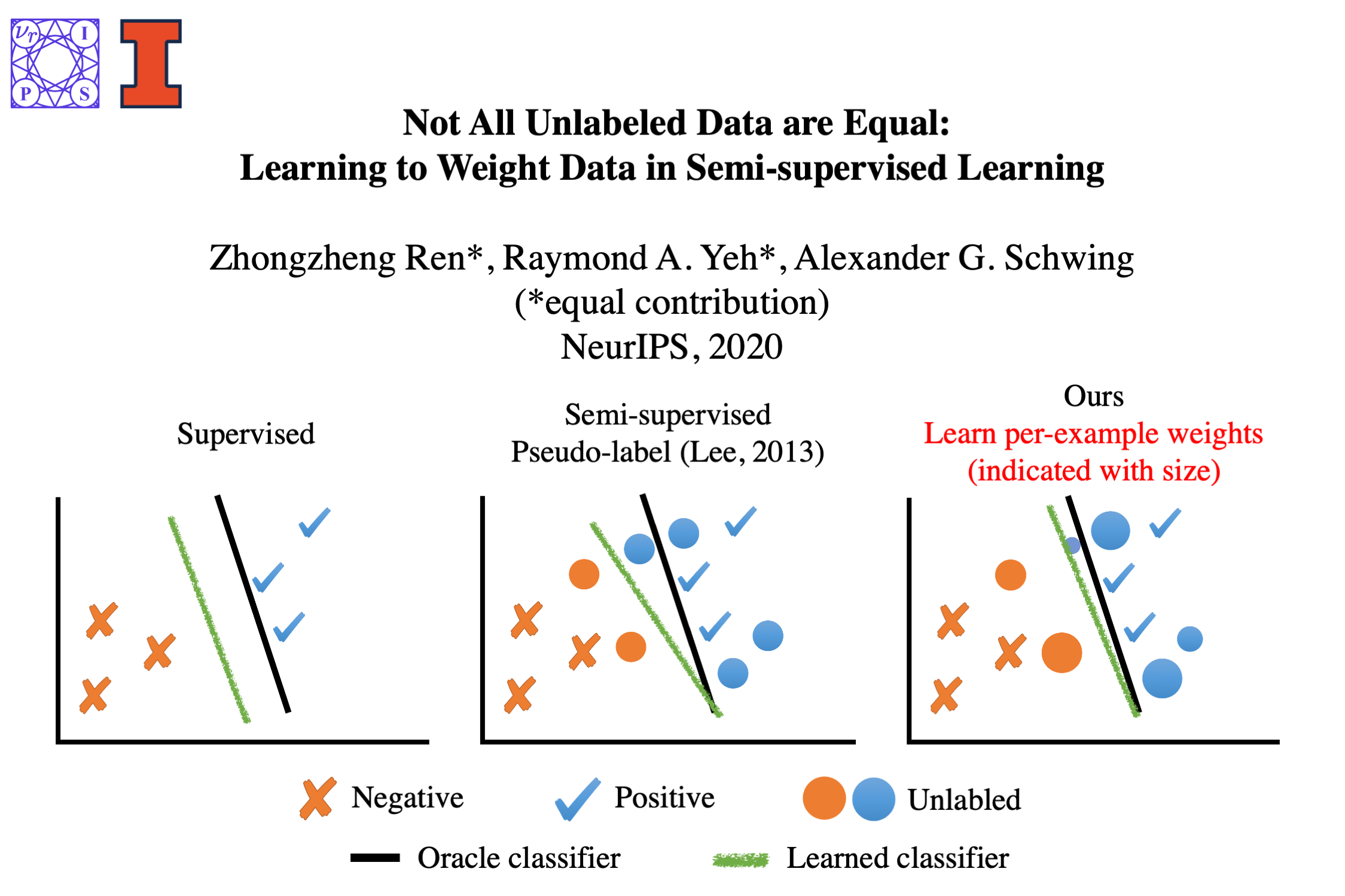 |
Related work
P. W. Koh and P. Liang,
Understanding black-box predictions via influence functions, ICML 2017.
K. Sohn, et al.,
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence, NeurIPS 2020.
Q. Xie, et al.,
Unsupervised Data Augmentation for Consistency Training, NeurIPS 2020.
J. Lorraine, et al.,
Optimizing Millions of Hyperparameters by Implicit Differentiation, AISTATS 2020.
Z. Ren, et al.,
UFO2: A Unified Framework towards Omni-supervised Object Detection, ECCV 2020.
Acknowledgement
This work is supported in part by NSF under Grant No. 1718221, 2008387 and MRI #1725729,
NIFA award 2020-67021-32799, UIUC, Samsung, Amazon, 3M, and Cisco Systems Inc. (Gift Award
CG 1377144). We thank Cisco for access to the Arcetri cluster. We thank Amazon for EC2 credits.
RY is supported by a Google PhD Fellowship. ZR is supported by Yunni & Maxine Pao Memorial Fellowship.
Thanks the SPADE folks for this beautiful webpage.