Publications
2026
-
 WildDet3D: Scaling Promptable 3D Detection in the WildWeikai Huang*, Jieyu Zhang*, Sijun Li, Taoyang Jia, Jiafei Duan, Yunqian Cheng, Jaemin Cho, Matthew Wallingford, Rustin Soraki, Chris Dongjoo Kim, and 8 more authorspreprint, 2026
WildDet3D: Scaling Promptable 3D Detection in the WildWeikai Huang*, Jieyu Zhang*, Sijun Li, Taoyang Jia, Jiafei Duan, Yunqian Cheng, Jaemin Cho, Matthew Wallingford, Rustin Soraki, Chris Dongjoo Kim, and 8 more authorspreprint, 2026Understanding objects in 3D from a single image is a cornerstone of spatial intelligence. A key step toward this goal is monocular 3D object detection—recovering the extent, location, and orientation of objects from an input RGB image. To be practical in the open world, such a detector must generalize beyond closed-set categories, support diverse prompt modalities, and leverage geometric cues when available. Progress is hampered by two bottlenecks: existing methods are designed for a single prompt type and lack a mechanism to incorporate additional geometric cues, and current 3D datasets cover only narrow categories in controlled environments, limiting open-world transfer. In this work we address both gaps. First, we introduce WildDet3D, a unified geometry-aware architecture that natively accepts text, point, and box prompts and can incorporate auxiliary depth signals at inference time. Second, we present WildDet3D-Data, the largest open 3D detection dataset to date, constructed by generating candidate 3D boxes from existing 2D annotations and retaining only human-verified ones, yielding over 1M images across 13.5K categories in diverse real-world scenes. WildDet3D establishes a new state-of-the-art across multiple benchmarks and settings. In the open-world setting, it achieves 22.6/24.8 AP3D on our newly introduced WildDet3D-Bench with text and box prompts. On Omni3D, it reaches 34.2/36.4 AP3D with text and box prompts, respectively. In zero-shot evaluation, it achieves 40.3/48.9 ODS on Argoverse 2 and ScanNet. Notably, incorporating depth cues at inference time yields substantial additional gains (+20.7 AP on average across settings).
@article{molmoweb2026, title = {WildDet3D: Scaling Promptable 3D Detection in the Wild}, author = {Huang, Weikai and Zhang, Jieyu and Li, Sijun and Jia, Taoyang and Duan, Jiafei and Cheng, Yunqian and Cho, Jaemin and Wallingford, Matthew and Soraki, Rustin and Kim, Chris Dongjoo and Liu, Shuo and Clay, Donovan and Anderson, Taira and Han, Winson and Farhadi, Ali and Hariharan, Bharath and Ren, Zhongzheng and Krishna, Ranjay}, journal = {preprint}, year = {2026}, } -
 MolmoWeb: Open Visual Web Agent and Open Data for the Open WebTanmay Gupta*, Piper Wolters*, Zixian Ma*, Peter Sushko*, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, and 6 more authorspreprint, 2026
MolmoWeb: Open Visual Web Agent and Open Data for the Open WebTanmay Gupta*, Piper Wolters*, Zixian Ma*, Peter Sushko*, Rock Yuren Pang, Diego Llanes, Yue Yang, Taira Anderson, Boyuan Zheng, Zhongzheng Ren, and 6 more authorspreprint, 2026Web agents—autonomous systems that navigate and execute tasks on the web on behalf of users—have the potential to transform how people interact with the digital world. However, the most capable web agents today rely on proprietary models with undisclosed training data and recipes, limiting scientific understanding, reproducibility, and community-driven progress. We believe agents for the open web should be built in the open. To this end, we introduce (1) MolmoWebMix, a large and diverse mixture of browser task demonstrations and web-GUI perception data and (2) MolmoWeb a family of fully open multimodal web agents. Specifically, MolmoWebMix combines over 100K synthetic task trajectories from multiple complementary generation pipelines with 30K+ human demonstrations, atomic web-skill trajectories, and GUI perception data, including referring expression grounding and screenshot question answering. MolmoWeb agents operate as instruction-conditioned visual-language action policies: given a task instruction and a webpage screenshot, they predict the next browser action, requiring no access to HTML, accessibility trees, or specialized APIs. Available in 4B and 8B size, on browser-use benchmarks like WebVoyager, Online-Mind2Web, and DeepShop, MolmoWeb agents achieve state-of-the-art results outperforming similar scale open-weight-only models such as Fara-7B, UI-Tars-1.5-7B, and Holo1-7B. MolmoWeb-8B also surpasses set-of-marks (SoM) agents built on much larger closed frontier models like GPT-4o. We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection, achieving 94.7% and 60.5% pass@4 (compared to 78.2% and 35.3% pass@1)on WebVoyager and Online-Mind2Web respectively. We will release model checkpoints, training data, code, and a unified evaluation harness to enable reproducibility and accelerate open research on web agents.
@article{molmoweb2027, title = {MolmoWeb: Open Visual Web Agent and Open Data for the Open Web}, author = {Gupta, Tanmay and Wolters, Piper and Ma, Zixian and Sushko, Peter and Pang, Rock Yuren and Llanes, Diego and Yang, Yue and Anderson, Taira and Zheng, Boyuan and Ren, Zhongzheng and Trivedi, Harsh and Blanton, Taylor and Ouellette, Caleb and Han, Winson and Farhadi, Ali and Krishna, Ranjay}, journal = {preprint}, year = {2026}, } -
 VFIG: Vectorizing Complex Figures in SVG with Vision-Language ModelsQijia He*, Xunmei Liu*, Hammaad Memon*, Ziang Li*, Zixian Ma*, Jaemin Cho, Zhongzheng Ren, Daniel S Weld, and Ranjay Krishna2026
VFIG: Vectorizing Complex Figures in SVG with Vision-Language ModelsQijia He*, Xunmei Liu*, Hammaad Memon*, Ziang Li*, Zixian Ma*, Jaemin Cho, Zhongzheng Ren, Daniel S Weld, and Ranjay Krishna2026Scalable Vector Graphics (SVG) are an essential format for technical illustration and digital design, offering precise resolution independence and flexible semantic editability. In practice, however, original vector source files are frequently lost or inaccessible, leaving only “flat” rasterized versions (e.g., PNG or JPEG) that are difficult to modify or scale. Manually reconstructing these figures is a prohibitively labor-intensive process, requiring specialized expertise to recover the original geometric intent. To bridge this gap, we propose VFIG, a family of Vision–Language Models trained for complex and high-fidelity figure-to-SVG conversion. While this task is inherently data-driven, existing datasets are typically small-scale and lack the complexity of professional diagrams. We address this by introducing VFIG-Data, a large-scale dataset of 66K high-quality figure–SVG pairs, curated from a diverse mix of real-world paper figures and procedurally generated diagrams. Recognizing that SVGs are composed of recurring primitives and hierarchical local structures, we introduce a coarse-to-fine training curriculum that begins with supervised fine-tuning (SFT) to learn atomic primitives and transitions to reinforcement learning (RL) refinement to optimize global diagram fidelity, layout consistency, and topological edge cases. Finally, we introduce VFIG-Bench, a comprehensive evaluation suite with novel metrics designed to measure the structural integrity of complex figures. VFIG achieves state-of-the-art performance among open-source models and performs on par with GPT-5.2, achieving a VLM-Judge score of 0.829 on VFIG-Bench.
@misc{he2026vfigvectorizingcomplexfigures, title = {VFIG: Vectorizing Complex Figures in SVG with Vision-Language Models}, author = {He, Qijia and Liu, Xunmei and Memon, Hammaad and Li, Ziang and Ma, Zixian and Cho, Jaemin and Ren, Zhongzheng and Weld, Daniel S and Krishna, Ranjay}, year = {2026}, eprint = {2603.24575}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, url = {https://arxiv.org/abs/2603.24575}, } -
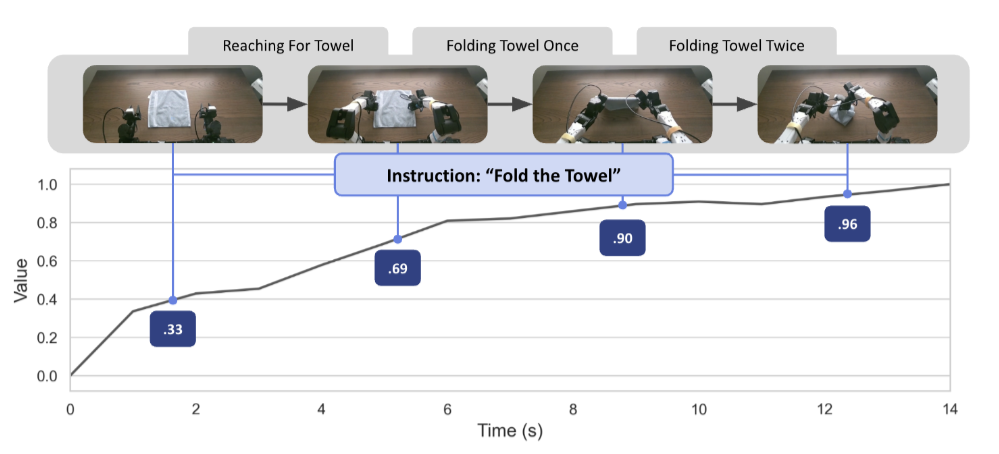 TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for RoboticsShirui Chen, Cole Harrison, Ying-Chun Lee, Angela Jin Yang, Zhongzheng Ren, Lillian J. Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna2026
TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for RoboticsShirui Chen, Cole Harrison, Ying-Chun Lee, Angela Jin Yang, Zhongzheng Ren, Lillian J. Ratliff, Jiafei Duan, Dieter Fox, and Ranjay Krishna2026While Vision-Language-Action (VLA) models have seen rapid progress in pretraining, their advancement in Reinforcement Learning (RL) remains hampered by low sample efficiency and sparse rewards in real-world settings. Developing generalizable process reward models is essential for providing the fine-grained feedback necessary to bridge this gap, yet existing temporal value functions often fail to generalize beyond their training domains. We introduce TOPReward, a novel, probabilistically grounded temporal value function that leverages the latent world knowledge of pretrained video Vision-Language Models (VLMs) to estimate robotic task progress. Unlike prior methods that prompt VLMs to directly output progress values, which are prone to numerical misrepresentation, TOPReward extracts task progress directly from the VLM’s internal token logits. In zero-shot evaluations across 130+ distinct real-world tasks and multiple robot platforms (e.g., Franka, YAM, SO-100/101), TOPReward achieves 0.947 mean Value-Order Correlation (VOC) on Qwen3-VL, dramatically outperforming the state-of-the-art GVL baseline which achieves near-zero correlation on the same open-source model. We further demonstrate that TOPReward serves as a versatile tool for downstream applications, including success detection and reward-aligned behavior cloning.
@misc{chen2026topreward, title = {TOPReward: Token Probabilities as Hidden Zero-Shot Rewards for Robotics}, author = {Chen, Shirui and Harrison, Cole and Lee, Ying-Chun and Yang, Angela Jin and Ren, Zhongzheng and Ratliff, Lillian J. and Duan, Jiafei and Fox, Dieter and Krishna, Ranjay}, year = {2026}, eprint = {2602.19313}, archiveprefix = {arXiv}, primaryclass = {cs.RO}, } -
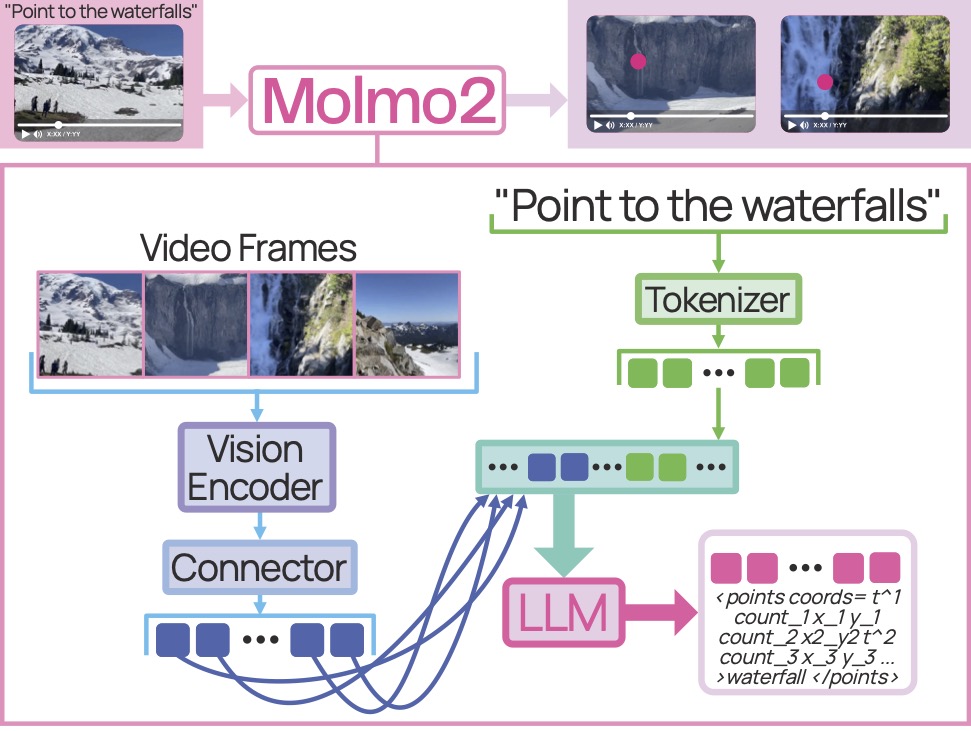 Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and GroundingChristopher Clark*, Jieyu Zhang*, Zixian Ma*, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, and 11 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026
Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and GroundingChristopher Clark*, Jieyu Zhang*, Zixian Ma*, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, and 11 more authorsIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026Today’s strongest video-language models (VLMs) remain proprietary. The strongest open-weight models either rely on synthetic data from proprietary VLMs, effectively distilling from them, or do not disclose their training data or recipe. As a result, the open-source community lacks the foundations needed to improve on the state-of-the-art video (and image) language models. Crucially, many downstream applications require more than just high-level video understanding; they require grounding—either by pointing or by tracking in pixels. Even proprietary models lack this capability. We present Molmo2, a new family of VLMs that are state-of-the-art among open-source models and demonstrate exceptional new capabilities in point-driven grounding in single image, multi-image, and video tasks. Our key contribution is a collection of 7 new video datasets and 2 multi-image datasets, including a dataset of highly detailed video captions for pre-training, a free-form video Q&A dataset for f ine-tuning, a new object tracking dataset with complex queries, and an innovative new video pointing dataset, all collected without the use of closed VLMs. We also present a training recipe for this data utilizing an efficient packing and message-tree encoding scheme, and show bi-directional attention on vision tokens and a novel token-weight strategy improves performance. Our best-in-class 8B model outperforms others in the class of open weight and data models on short videos, counting, and captioning, and is competitive on long-videos. On video-grounding Molmo2 significantly outperforms existing open-weight models like Qwen3-VL (35.5 vs 29.6 accuracy on video counting) and surpasses proprietary models like Gemini 3 Pro on some tasks (38.4 vs 20.0 F1 on video pointing and 56.2 vs 41.1 J&F on video tracking).
@inproceedings{clark2025molmo2_cvpr26, title = {Molmo2: Open Weights and Data for Vision-Language Models with Video Understanding and Grounding}, author = {Clark, Christopher and Zhang, Jieyu and Ma, Zixian and Park, Jae Sung and Salehi, Mohammadreza and Tripathi, Rohun and Lee, Sangho and Ren, Zhongzheng and Kim, Chris Dongjoo and Yang, Yinuo and Shao, Vincent and Yang, Yue and Huang, Weikai and Gao, Ziqi and Anderson, Taira and Zhang, Jianrui and Jain, Jitesh and Stoica, George and Han, Winston and Farhadi, Ali and Krishna, Ranjay}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2026}, }
2024
-
 Apple Intelligence Foundation Language ModelsTom Gunter, Zirui Wang, Chong Wang, Ruoming Pang, Andy Narayanan, Aonan Zhang, Bowen Zhang, Chen Chen, Chung-Cheng Chiu, David Qiu, and 145 more authors2024
Apple Intelligence Foundation Language ModelsTom Gunter, Zirui Wang, Chong Wang, Ruoming Pang, Andy Narayanan, Aonan Zhang, Bowen Zhang, Chen Chen, Chung-Cheng Chiu, David Qiu, and 145 more authors2024We present foundation language models developed to power Apple Intelligence features, including a 3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
@misc{gunter2024appleintelligencefoundationlanguage, title = {Apple Intelligence Foundation Language Models}, author = {Gunter, Tom and Wang, Zirui and Wang, Chong and Pang, Ruoming and Narayanan, Andy and Zhang, Aonan and Zhang, Bowen and Chen, Chen and Chiu, Chung-Cheng and Qiu, David and Gopinath, Deepak and Yap, Dian Ang and Yin, Dong and Nan, Feng and Weers, Floris and Yin, Guoli and Huang, Haoshuo and Wang, Jianyu and Lu, Jiarui and Peebles, John and Ye, Ke and Lee, Mark and Du, Nan and Chen, Qibin and Keunebroek, Quentin and Wiseman, Sam and Evans, Syd and Lei, Tao and Rathod, Vivek and Kong, Xiang and Du, Xianzhi and Li, Yanghao and Wang, Yongqiang and Gao, Yuan and Ahmed, Zaid and Xu, Zhaoyang and Lu, Zhiyun and Rashid, Al and Jose, Albin Madappally and Doane, Alec and Bencomo, Alfredo and Vanderby, Allison and Hansen, Andrew and Jain, Ankur and Anupama, Anupama Mann and Kamal, Areeba and Wu, Bugu and Brum, Carolina and Maalouf, Charlie and Erdenebileg, Chinguun and Dulhanty, Chris and Moritz, Dominik and Kang, Doug and Jimenez, Eduardo and Ladd, Evan and Shi, Fangping and Bai, Felix and Chu, Frank and Hohman, Fred and Kotek, Hadas and Coleman, Hannah Gillis and Li, Jane and Bigham, Jeffrey and Cao, Jeffery and Lai, Jeff and Cheung, Jessica and Shan, Jiulong and Zhou, Joe and Li, John and Qin, Jun and Singh, Karanjeet and Vega, Karla and Zou, Kelvin and Heckman, Laura and Gardiner, Lauren and Bowler, Margit and Cordell, Maria and Cao, Meng and Hay, Nicole and Shahdadpuri, Nilesh and Godwin, Otto and Dighe, Pranay and Rachapudi, Pushyami and Tantawi, Ramsey and Frigg, Roman and Davarnia, Sam and Shah, Sanskruti and Guha, Saptarshi and Sirovica, Sasha and Ma, Shen and Ma, Shuang and Wang, Simon and Kim, Sulgi and Jayaram, Suma and Shankar, Vaishaal and Paidi, Varsha and Kumar, Vivek and Wang, Xin and Zheng, Xin and Cheng, Walker and Shrager, Yael and Ye, Yang and Tanaka, Yasu and Guo, Yihao and Meng, Yunsong and Luo, Zhao Tang and Ouyang, Zhi and Aygar, Alp and Wan, Alvin and Walkingshaw, Andrew and Narayanan, Andy and Lin, Antonie and Farooq, Arsalan and Ramerth, Brent and Reed, Colorado and Bartels, Chris and Chaney, Chris and Riazati, David and Yang, Eric Liang and Feldman, Erin and Hochstrasser, Gabriel and Seguin, Guillaume and Belousova, Irina and Pelemans, Joris and Yang, Karen and Vahid, Keivan Alizadeh and Cao, Liangliang and Najibi, Mahyar and Zuliani, Marco and Horton, Max and Cho, Minsik and Bhendawade, Nikhil and Dong, Patrick and Maj, Piotr and Agrawal, Pulkit and Shan, Qi and Fu, Qichen and Poston, Regan and Xu, Sam and Liu, Shuangning and Rao, Sushma and Heeramun, Tashweena and Merth, Thomas and Rayala, Uday and Cui, Victor and Sridhar, Vivek Rangarajan and Zhang, Wencong and Zhang, Wenqi and Wu, Wentao and Zhou, Xingyu and Liu, Xinwen and Zhao, Yang and Xia, Yin and Ren, Zhile and Ren, Zhongzheng}, year = {2024}, eprint = {2407.21075}, archiveprefix = {arXiv}, primaryclass = {cs.AI}, } -
 NeRFDeformer: NeRF Transformation from a Single View via 3D Scene FlowsZhenggang Tang, Zhongzheng Ren, Xiaoming Zhao, Bowen Wen, Jonathan Tremblay, Stan Birchfield, and Alexander SchwingIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
NeRFDeformer: NeRF Transformation from a Single View via 3D Scene FlowsZhenggang Tang, Zhongzheng Ren, Xiaoming Zhao, Bowen Wen, Jonathan Tremblay, Stan Birchfield, and Alexander SchwingIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024We present a method for automatically modifying a NeRF representation based on a single observation of a non-rigid transformed version of the original scene. Our method defines the transformation as a 3D flow, specifically as a weighted linear blending of rigid transformations of 3D anchor points that are defined on the surface of the scene. In order to identify anchor points, we introduce a novel correspondence algorithm that first matches RGB-based pairs, then leverages multi-view information and 3D reprojection to robustly filter false positives in two steps. We also introduce a new dataset for exploring the problem of modifying a NeRF scene through a single observation. Our dataset ( this https URL ) contains 113 synthetic scenes leveraging 47 3D assets. We show that our proposed method outperforms NeRF editing methods as well as diffusion-based methods, and we also explore different methods for filtering correspondences.
@inproceedings{Tang_2024_CVPR, author = {Tang, Zhenggang and Ren, Zhongzheng and Zhao, Xiaoming and Wen, Bowen and Tremblay, Jonathan and Birchfield, Stan and Schwing, Alexander}, title = {NeRFDeformer: NeRF Transformation from a Single View via 3D Scene Flows}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, } -
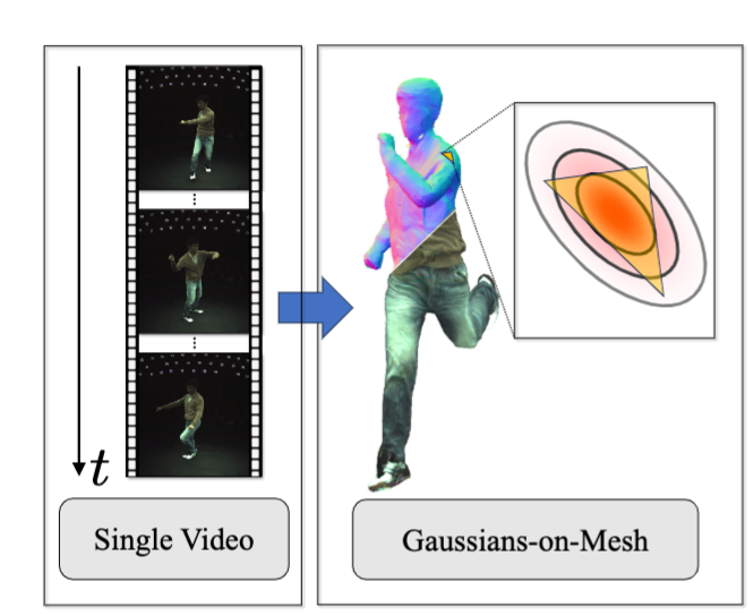 GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-MeshIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-MeshIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024We introduce GoMAvatar, a novel approach for real-time, memory-efficient, high-quality animatable human modeling. GoMAvatar takes as input a single monocular video to create a digital avatar capable of re-articulation in new poses and real-time rendering from novel viewpoints, while seamlessly integrating with rasterization-based graphics pipelines. Central to our method is the Gaussians-on-Mesh representation, a hybrid 3D model combining rendering quality and speed of Gaussian splatting with geometry modeling and compatibility of deformable meshes. We assess GoMAvatar on ZJU-MoCap data and various YouTube videos. GoMAvatar matches or surpasses current monocular human modeling algorithms in rendering quality and significantly outperforms them in computational efficiency (43 FPS) while being memory-efficient (3.63 MB per subject
@inproceedings{wen2024gomavatar, title = {{GoMAvatar: Efficient Animatable Human Modeling from Monocular Video Using Gaussians-on-Mesh}}, author = {Wen, Jing and Zhao, Xiaoming and Ren, Zhongzheng and Schwing, Alexander and Wang, Shenlong}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2024}, } -
 PhysGen: Rigid-Body Physics-Grounded Image-to-Video GenerationIn European Conference on Computer Vision (ECCV), 2024
PhysGen: Rigid-Body Physics-Grounded Image-to-Video GenerationIn European Conference on Computer Vision (ECCV), 2024We present PhysGen, a novel image-to-video generation method that converts a single image and an input condition (e.g., force and torque applied to an object in the image) to produce a realistic, physically plausible, and temporally consistent video. Our key insight is to integrate model-based physical simulation with a data-driven video generation process, enabling plausible image-space dynamics. At the heart of our system are three core components: (i) an image understanding module that effectively captures the geometry, materials, and physical parameters of the image; (ii) an image-space dynamics simulation model that utilizes rigid-body physics and inferred parameters to simulate realistic behaviors; and (iii) an image-based rendering and refinement module that leverages generative video diffusion to produce realistic video footage featuring the simulated motion. The resulting videos are realistic in both physics and appearance and are even precisely controllable, showcasing superior results over existing data-driven image-to-video generation works through quantitative comparison and comprehensive user study. PhysGen’s resulting videos can be used for various downstream applications, such as turning an image into a realistic animation or allowing users to interact with the image and create various dynamics
@inproceedings{liu2024physgen, title = {PhysGen: Rigid-Body Physics-Grounded Image-to-Video Generation}, author = {Liu, Shaowei and Ren, Zhongzheng and Gupta, Saurabh and Wang, Shenlong}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2024}, }
2023
-
 Occupancy Planes for Single-view RGB-D Human ReconstructionIn AAAI Conference on Artificial Intelligence (AAAI), 2023
Occupancy Planes for Single-view RGB-D Human ReconstructionIn AAAI Conference on Artificial Intelligence (AAAI), 2023Single-view RGB-D human reconstruction with implicit functions is often formulated as per-point classification. Specifically, a set of 3D locations within the view-frustum of the camera are first projected independently onto the image and a corresponding feature is subsequently extracted for each 3D location. The feature of each 3D location is then used to classify independently whether the corresponding 3D point is inside or outside the observed object. This procedure leads to sub-optimal results because correlations between predictions for neighboring locations are only taken into account implicitly via the extracted features. For more accurate results we propose the occupancy planes (OPlanes) representation, which enables to formulate single-view RGB-D human reconstruction as occupancy prediction on planes which slice through the camera’s view frustum. Such a representation provides more flexibility than voxel grids and enables to better leverage correlations than per-point classification. On the challenging S3D data we observe a simple classifier based on the OPlanes representation to yield compelling results, especially in difficult situations with partial occlusions due to other objects and partial visibility, which haven’t been addressed by prior work.
@inproceedings{zhao-oplane2023, title = {Occupancy Planes for Single-view RGB-D Human Reconstruction}, author = {Zhao, Xiaoming and Hu, Yuan-Ting and Ren, Zhongzheng and Schwing, Alexander}, booktitle = {AAAI Conference on Artificial Intelligence (AAAI)}, year = {2023}, } -
 StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3DPengsheng Guo, Hans Hao, Adam Caccavale, Zhongzheng Ren, Edward Zhang, Qi Shan, Aditya Sankar, Alexander Schwing, Alex Colburn, and Fangchang Ma2023
StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3DPengsheng Guo, Hans Hao, Adam Caccavale, Zhongzheng Ren, Edward Zhang, Qi Shan, Aditya Sankar, Alexander Schwing, Alex Colburn, and Fangchang Ma2023In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
@misc{guo2023stabledreamer, title = {StableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D}, author = {Guo, Pengsheng and Hao, Hans and Caccavale, Adam and Ren, Zhongzheng and Zhang, Edward and Shan, Qi and Sankar, Aditya and Schwing, Alexander and Colburn, Alex and Ma, Fangchang}, year = {2023}, eprint = {2312.02189}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, }
2022
-
 CASA: Category-agnostic Skeletal Animal ReconstructionIn Neural Information Processing Systems (NeurIPS), 2022
CASA: Category-agnostic Skeletal Animal ReconstructionIn Neural Information Processing Systems (NeurIPS), 2022Recovering the skeletal shape of an animal from a monocular video is a longstanding challenge. Prevailing animal reconstruction methods often adopt a control-point driven animation model and optimize bone transforms individually without considering skeletal topology, yielding unsatisfactory shape and articulation. In contrast, humans can easily infer the articulation structure of an unknown animal by associating it with a seen articulated character in their memory. Inspired by this fact, we present CASA, a novel Category-Agnostic Skeletal Animal reconstruction method consisting of two major components: a video-to-shape retrieval process and a neural inverse graphics framework. During inference, CASA first retrieves an articulated shape from a 3D character assets bank so that the input video scores highly with the rendered image, according to a pretrained language-vision model. CASA then integrates the retrieved character into an inverse graphics framework and jointly infers the shape deformation, skeleton structure, and skinning weights through optimization. Experiments validate the efficacy of CASA regarding shape reconstruction and articulation. We further demonstrate that the resulting skeletal-animated characters can be used for re-animation.
@inproceedings{wu2022casa, title = {{CASA}: Category-agnostic Skeletal Animal Reconstruction}, author = {Wu, Yuefan and Chen, Zeyuan and Liu, Shaowei and Ren, Zhongzheng and Wang, Shenlong}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2022}, } -
 Total Variation Optimization Layers for Computer VisionIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
Total Variation Optimization Layers for Computer VisionIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022Optimization within a layer of a deep-net has emerged as a new direction for deep-net layer design. However, there are two main challenges when applying these layers to computer vision tasks: (a) which optimization problem within a layer is useful?; (b) how to ensure that computation within a layer remains efficient? To study question (a), in this work, we propose total variation (TV) minimization as a layer for computer vision. Motivated by the success of total variation in image processing, we hypothesize that TV as a layer provides useful inductive bias for deep-nets too. We study this hypothesis on five computer vision tasks: image classification, weakly supervised object localization, edge-preserving smoothing, edge detection, and image denoising, improving over existing baselines. To achieve these results we had to address question (b): we developed a GPU-based projectedNewton method which is 37 faster than existing solutions.
@inproceedings{YehCVPR2022, author = {Yeh, Raymond A. and Hu, Yuan-Ting and Ren, Zhongzheng and Schwing, Alexander}, title = {Total Variation Optimization Layers for Computer Vision}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2022}, }
2021
-
 Class-agnostic Reconstruction of Dynamic Objects from VideosZhongzheng Ren∗, Xiaoming Zhao∗, and Alexander SchwingIn Neural Information Processing Systems (NeurIPS), 2021
Class-agnostic Reconstruction of Dynamic Objects from VideosZhongzheng Ren∗, Xiaoming Zhao∗, and Alexander SchwingIn Neural Information Processing Systems (NeurIPS), 2021We introduce REDO, a class-agnostic framework to REconstruct the Dynamic Objects from RGBD or calibrated videos. Compared to prior work, our problem setting is more realistic yet more challenging for three reasons: 1) due to occlusion or camera settings an object of interest may never be entirely visible, but we aim to reconstruct the complete shape; 2) we aim to handle different object dynamics including rigid motion, non-rigid motion, and articulation; 3) we aim to reconstruct different categories of objects with one unified framework. To address these challenges, we develop two novel modules. First, we introduce a canonical 4D implicit function which is pixel-aligned with aggregated temporal visual cues. Second, we develop a 4D transformation module which captures object dynamics to support temporal propagation and aggregation. We study the efficacy of REDO in extensive experiments on synthetic RGBD video datasets SAIL-VOS 3D and DeformingThings4D++, and on real-world video data 3DPW. We find REDO outperforms state-of-the-art dynamic reconstruction methods by a margin. In ablation studies we validate each developed component.
@inproceedings{ren-redo2021, title = {Class-agnostic Reconstruction of Dynamic Objects from Videos}, author = {Ren$\ast$, Zhongzheng and Zhao$\ast$, Xiaoming and Schwing, Alexander}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2021}, } -
 Semantic Tracklets: An Object-Centric Representation for Visual Multi-Agent Reinforcement LearningIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021
Semantic Tracklets: An Object-Centric Representation for Visual Multi-Agent Reinforcement LearningIn IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021Solving complex real-world tasks, e.g., autonomous fleet control, often involves a coordinated team of multiple agents which learn strategies from visual inputs via reinforcement learning. Many existing multi-agent reinforcement learning (MARL) algorithms however don’t scale to environments where agents operate on visual inputs. To address this issue, algorithmically, recent works have focused on non-stationarity and exploration. In contrast, we study whether scalability can also be achieved via a disentangled representation. For this, we explicitly construct an object-centric intermediate representation to characterize the states of an environment, which we refer to as ‘semantic tracklets.’ We evaluate ‘semantic tracklets’ on the visual multi-agent particle environment (VMPE) and on the challenging visual multi-agent GFootball environment. ‘Semantic tracklets’ consistently outperform baselines on VMPE, and achieve a +2.4 higher score difference than baselines on GFootball. Notably, this method is the first to successfully learn a strategy for five players in the GFootball environment using only visual data.
@inproceedings{semtrack-2021, title = {Semantic Tracklets: An Object-Centric Representation for Visual Multi-Agent Reinforcement Learning}, author = {Liu$\ast$, Iou-Jen and Ren$\ast$, Zhongzheng and Yeh$\ast$, Raymond A. and Schwing, Alexander}, booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)}, year = {2021}, } -
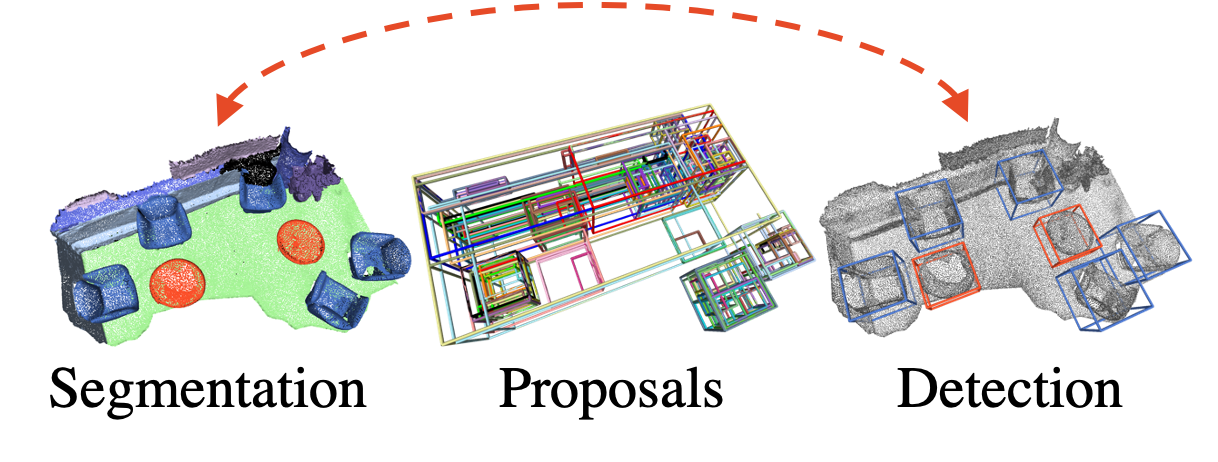 3D Spatial Recognition without Spatially Labeled 3DIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021
3D Spatial Recognition without Spatially Labeled 3DIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021We introduce WyPR, a Weakly-supervised framework for Point cloud Recognition, requiring only scene-level class tags as supervision. WyPR jointly addresses three core 3D recognition tasks: point-level semantic segmentation, 3D proposal generation, and 3D object detection, coupling their predictions through self and cross-task consistency losses. We show that in conjunction with standard multiple-instance learning objectives, WyPR can detect and segment objects in point cloud data without access to any spatial labels at training time. We demonstrate its efficacy using the ScanNet and S3DIS datasets, outperforming prior state of the art on weakly-supervised segmentation by more than 6% mIoU. In addition, we set up the first benchmark for weakly-supervised 3D object detection on both datasets, where WyPR outperforms standard approaches and establishes strong baselines for future work.
@inproceedings{ren2021wypr, title = {3D Spatial Recognition without Spatially Labeled 3D}, author = {Ren, Zhongzheng and Misra, Ishan and Schwing, Alexander and Girdhar, Rohit}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2021}, }
2020
-
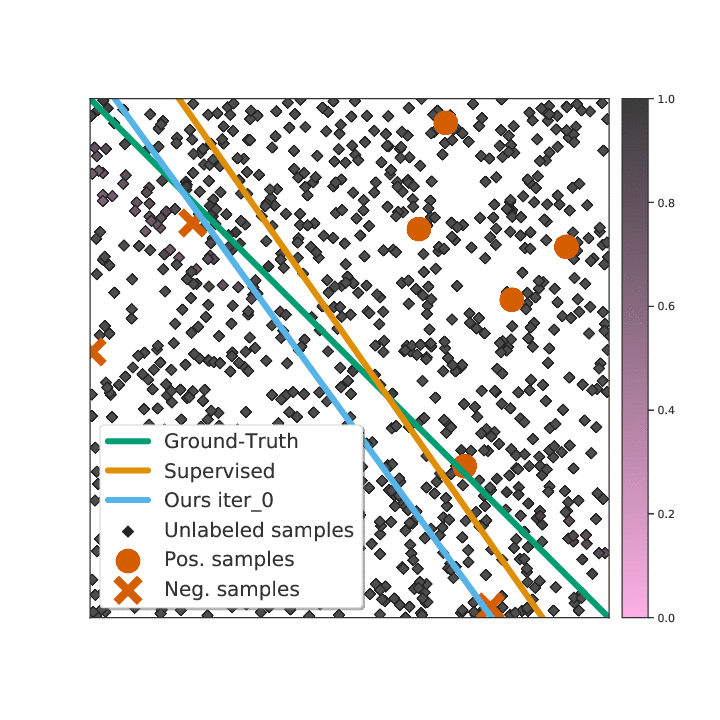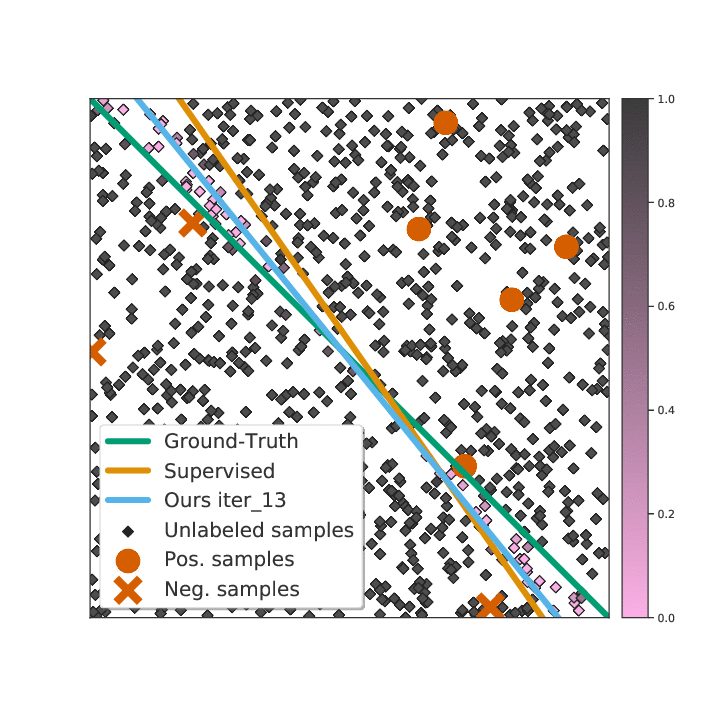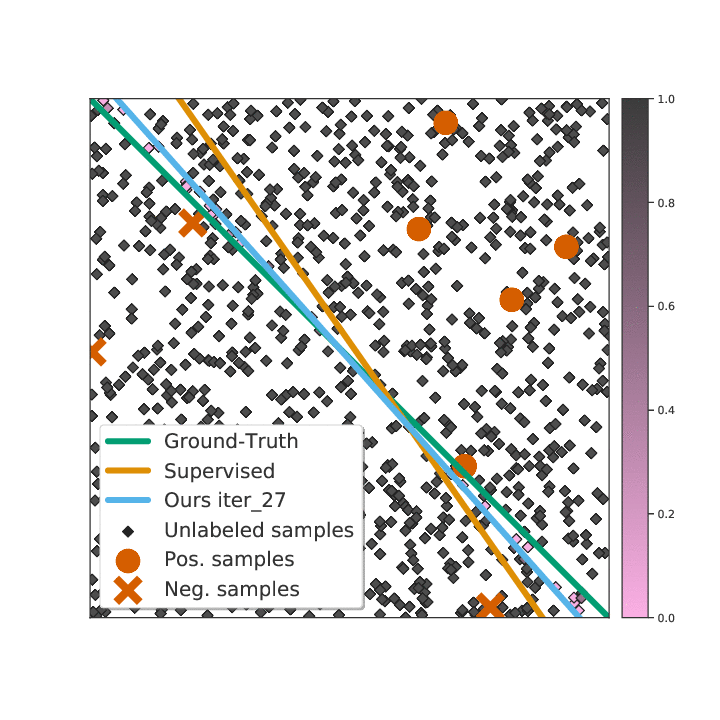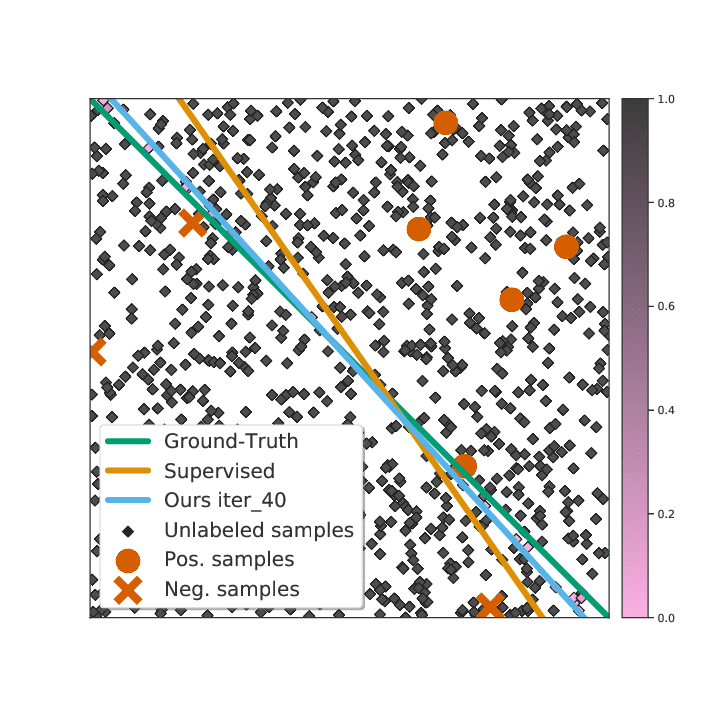 Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised LearningZhongzheng Ren∗, Raymond A. Yeh∗, and Alexander SchwingIn Neural Information Processing Systems (NeurIPS), 2020
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised LearningZhongzheng Ren∗, Raymond A. Yeh∗, and Alexander SchwingIn Neural Information Processing Systems (NeurIPS), 2020Existing semi-supervised learning (SSL) algorithms use a single weight to balance the loss of labeled and unlabeled examples, i.e., all unlabeled examples are equally weighted. But not all unlabeled data are equal. In this paper we study how to use a different weight for every unlabeled example. Manual tuning of all those weights– as done in prior work– is no longer possible. Instead, we adjust those weights via an algorithm based on the influence function, a measure of a model’s dependency on one training example. To make the approach efficient, we propose a fast and effective approximation of the influence function. We demonstrate that this technique outperforms state-of-the-art methods on semi-supervised image and language classification tasks.
@inproceedings{ren-ssl2020, title = {Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning}, author = {Ren$\ast$, Zhongzheng and Yeh$\ast$, Raymond A. and Schwing, Alexander}, booktitle = {Neural Information Processing Systems (NeurIPS)}, year = {2020}, } -
 UFO2: A Unified Framework towards Omni-supervised Object DetectionIn European Conference on Computer Vision (ECCV), 2020
UFO2: A Unified Framework towards Omni-supervised Object DetectionIn European Conference on Computer Vision (ECCV), 2020Existing work on object detection often relies on a single form of annotation: the model is trained using either accurate yet costly bounding boxes or cheaper but less expressive image-level tags. However, real-world annotations are often diverse in form, which challenges these existing works. In this paper, we present UFO2, a unified object detection framework that can handle different forms of supervision simultaneously. Specifically, UFO2 incorporates strong supervision (e.g., boxes), various forms of partial supervision (e.g., class tags, points, and scribbles), and unlabeled data. Through rigorous evaluations, we demonstrate that each form of label can be utilized to either train a model from scratch or to further improve a pre-trained model. We also use UFO2 to investigate budget-aware omni-supervised learning, i.e., various annotation policies are studied under a fixed annotation budget: we show that competitive performance needs no strong labels for all data. Finally, we demonstrate the generalization of UFO2, detecting more than 1,000 different objects without bounding box annotations.
@inproceedings{ren-eccv2020, title = {{UFO}$2$: A Unified Framework towards Omni-supervised Object Detection}, author = {Ren, Zhongzheng and Yu, Zhiding and Yang, Xiaodong and Liu, Ming-Yu and Schwing, Alexander and Kautz, Jan}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2020}, } -
 Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object DetectionZhongzheng Ren, Zhiding Yu, Xiaodong Yang, Ming-Yu Liu, Yong Jae Lee, Alexander Schwing, and Jan KautzIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020
Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object DetectionZhongzheng Ren, Zhiding Yu, Xiaodong Yang, Ming-Yu Liu, Yong Jae Lee, Alexander Schwing, and Jan KautzIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020Weakly supervised learning has emerged as a compelling tool for object detection by reducing the need for strong supervision during training. However, major challenges remain: (1) differentiation of object instances can be ambiguous; (2) detectors tend to focus on discriminative parts rather than entire objects; (3) without ground truth, object proposals have to be redundant for high recalls, causing significant memory consumption. Addressing these challenges is difficult, as it often requires to eliminate uncertainties and trivial solutions. To target these issues we develop an instance-aware and context-focused unified framework. It employs an instance-aware self-training algorithm and a learnable Concrete DropBlock while devising a memoryefficient sequential batch back-propagation. Our proposed method achieves state-of-the-art results on COCO (12.1% Missing Instance Grouped Instance Part Domination AP, 24.8% AP50), VOC 2007 (54.9% AP), and VOC 2012 (52.1% AP), improving baselines by great margins. In addition, the proposed method is the first to benchmark ResNet based models and weakly supervised video object detection. Code, models, and more details will be made available at: https://github.com/NVlabs/wetectron.
@inproceedings{ren-cvpr2020, title = {Instance-aware, Context-focused, and Memory-efficient Weakly Supervised Object Detection}, author = {Ren, Zhongzheng and Yu, Zhiding and Yang, Xiaodong and Liu, Ming-Yu and Lee, Yong Jae and Schwing, Alexander and Kautz, Jan}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2020}, }
2018
-
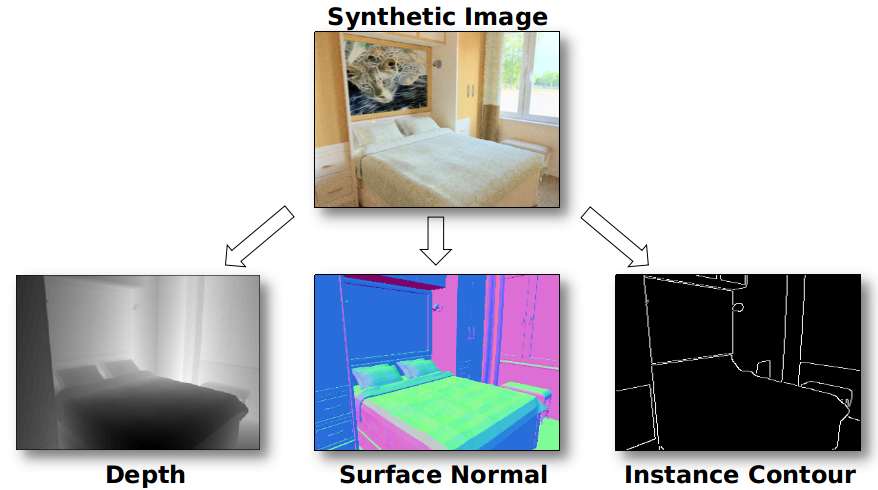 Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic ImageryZhongzheng Ren and Yong Jae LeeIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018
Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic ImageryZhongzheng Ren and Yong Jae LeeIn IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018In human learning, it is common to use multiple sources of information jointly. However, most existing feature learning approaches learn from only a single task. In this paper, we propose a novel multi-task deep network to learn generalizable high-level visual representations. Since multi-task learning requires annotations for multiple properties of the same training instance, we look to synthetic images to train our network. To overcome the domain difference between real and synthetic data, we employ an unsupervised feature space domain adaptation method based on adversarial learning. Given an input synthetic RGB image, our network simultaneously predicts its surface normal, depth, and instance contour, while also minimizing the feature space domain differences between real and synthetic data. Through extensive experiments, we demonstrate that our network learns more transferable representations compared to single-task baselines. Our learned representation produces state-of-the-art transfer learning results on PASCAL VOC 2007 classification and 2012 detection.
@inproceedings{ren-cvpr2018, title = {Cross-Domain Self-supervised Multi-task Feature Learning using Synthetic Imagery}, author = {Ren, Zhongzheng and Lee, Yong Jae}, booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2018}, } -
 Learning to Anonymize Faces for Privacy Preserving Action DetectionZhongzheng Ren, Yong Jae Lee, and Michael S. RyooIn European Conference on Computer Vision (ECCV), 2018
Learning to Anonymize Faces for Privacy Preserving Action DetectionZhongzheng Ren, Yong Jae Lee, and Michael S. RyooIn European Conference on Computer Vision (ECCV), 2018There is an increasing concern in computer vision devices invading users’ privacy by recording unwanted videos. On the one hand, we want the camera systems to recognize important events and assist human daily lives by understanding its videos, but on the other hand we want to ensure that they do not intrude people’s privacy. In this paper, we propose a new principled approach for learning a video \emphface anonymizer. We use an adversarial training setting in which two competing systems fight: (1) a video anonymizer that modifies the original video to remove privacy-sensitive information while still trying to maximize spatial action detection performance, and (2) a discriminator that tries to extract privacy-sensitive information from the anonymized videos. The end result is a video anonymizer that performs pixel-level modifications to anonymize each person’s face, with minimal effect on action detection performance. We experimentally confirm the benefits of our approach compared to conventional hand-crafted anonymization methods including masking, blurring, and noise adding.
@inproceedings{ren_privacy_2018, author = {Ren, Zhongzheng and Lee, Yong Jae and Ryoo, Michael S.}, title = {Learning to Anonymize Faces for Privacy Preserving Action Detection}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2018}, }
2017
-
 Who moved my cheese? Automatic Annotation of Rodent Behaviors with Convolutional Neural NetworksZhongzheng Ren, Adriana Noronha, Annie Vogel Ciernia, and Yong Jae LeeIn Winter Conference on Applications of Computer Vision (WACV), 2017
Who moved my cheese? Automatic Annotation of Rodent Behaviors with Convolutional Neural NetworksZhongzheng Ren, Adriana Noronha, Annie Vogel Ciernia, and Yong Jae LeeIn Winter Conference on Applications of Computer Vision (WACV), 2017In neuroscience, understanding animal behaviors is key to studying their memory patterns. Meanwhile, this is also the most time-consuming and difficult process because it relies heavily on humans to manually annotate the videos recording the animals. In this paper, we present a visual recognition system to automatically annotate animal behaviors to save human annotation costs. By treating the annotation task as a per-frame action classification problem, we can fine-tune a powerful pre-trained convolutional neural network (CNN) for this task. Through extensive experiments, we demonstrate our model not only provides more accurate annotations than alternate automatic methods, but also provides reliable annotations that can replace human annotations for neuroscience experiments.
@inproceedings{ren-wacv2017, title = {Who moved my cheese? Automatic Annotation of Rodent Behaviors with Convolutional Neural Networks}, author = {Ren, Zhongzheng and Noronha, Adriana and Ciernia, Annie Vogel and Lee, Yong Jae}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, year = {2017}, }