Cross-Domain Self-supervised Multi-task
Feature Learning using Synthetic Imagery
|
|
|
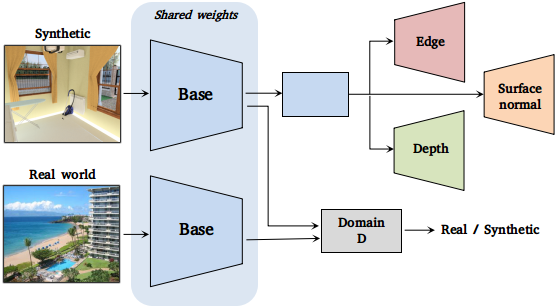
Abstract
In human learning, it is common to use multiple sources of information jointly. However, most existing feature learning approaches learn from only a single task. In this paper, we propose a novel multi-task deep network to learn generalizable high-level visual representations. Since multi-task learning requires annotations for multiple properties of the same training instance, we look to synthetic images to train our network. To overcome the domain difference between real and synthetic data, we employ an unsupervised feature space domain adaptation method based on adversarial learning. Given an input synthetic RGB image, our network simultaneously predicts its surface normal, depth, and instance contour, while also minimizing the feature space domain differences between real and synthetic data. Through extensive experiments, we demonstrate that our network learns more transferable representations compared to single-task baselines. Our learned representation produces state-of-the-art transfer learning results on PASCAL VOC 2007 classification and 2012 detection.

Materials
Code
Talk
In July 2018, I gave a talk in Chinese at leiphone.com. You can watch the video here.
Acknowledgments
This work was supported in part by the National Science Foundation under Grant No. 1748387, the AWS Cloud Credits for Research Program, and GPUs donated by NVIDIA. Any opinions, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of the National Science Foundation.
Comments, questions to Jason Ren